一时free一时happy,一直free一直happy
上线一周,
gemini-2.0-flash-exp、gemini-2.0-flash-thinking-exp 已经成为了我日常对话频率最高的模型之一。
看着名字很长,其实就是对标 GPT-4o 和 o1。
2.0-flash 在 SWE-bench(代码能力评估) 得分超过 Claude-Sonnet-3.5,2.0-flash-thinking 在 LMArena 所有类别拿到冠军,且速度比 o1 快 5 倍!
重要的是,他们还把思考过程公开了(o1每次都会因为这点被吐槽)
还有还有,不同于贵到肉疼的 o1 API,
也区别于“升级版封号斗罗pro-max-plus-ultra”的 Claude(额度是上午充的,号是中午没的。。。)
Gemini 它免费啊!
这就能做很多事了,翻译、编程、日常对话、联网搜索、中文视频聊天、视频剪辑、屏幕共享,把我其他AI应用的活也抢了。
之前用别家模型的 API 是为了节约成本,这次是真的离不开 Gemini 了。

上一次,我是因为 API 价格跳水,梳理了在日常工作流里面如何搭配不同模型的 API 和网页版。
当时我的选择是:
- 日常对话:Gemini 1.5 Flash
- 翻译:Llama-3.1-70B
- 代码:Deepseek-V2.5
- 本地:qwen-7b-instruct-q5_K_M
- 网页版:GPT-4o
使用OpenAI API的最后一条路断了,我连夜组合出了新的平价方案
但经过这两周的反复尝试后,这几个应用都被 Gemini 取代了,好处就是不需要自建服务集合十来个API,也不需要担心费用了。
官方的羊毛好暖好贴心~
一、日常对话 & 联网搜索
先来简单说说,如何获取 Gemini 的 API Key:
- 访问 https://makersuite.google.com/
- 用账号登录,点击 Get API Key -> Create API key in new project
- 得到的 Key 就是我们后面所有的设置里的“万能钥匙”了
本地的大模型对话端我还是推 Chatbox,作者的更新是真的快,我是自来水💦

最近更新还支持了联网、图片预处理
软件操作界面的右下角“设置”里面就可以选择 Gemini,Chatbox 支持了几乎是全系列的模型,单单是Gemini 系列足足有30个。
再分享一下我的默认设置:上下文消息上限保留12-18个、Temperature保留0.5~0.7。
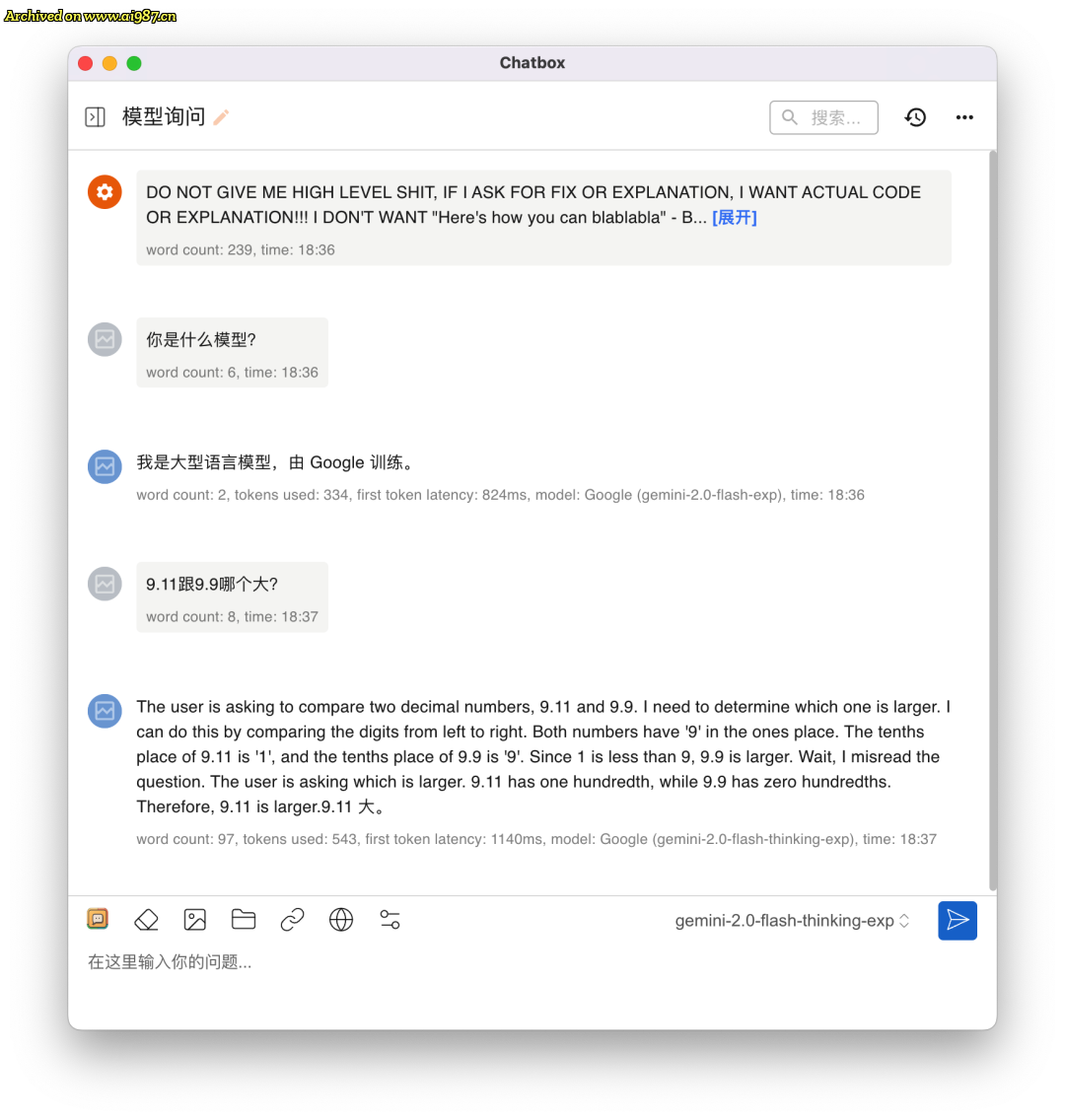
能回答“9.11跟9.9哪个大”的推理模型免费用上了!
再来就是高频的使用场景 – 代码生成了。
Cursor已经算是半取代我的 vscode,我的 vscode 现在只出现在云端了。
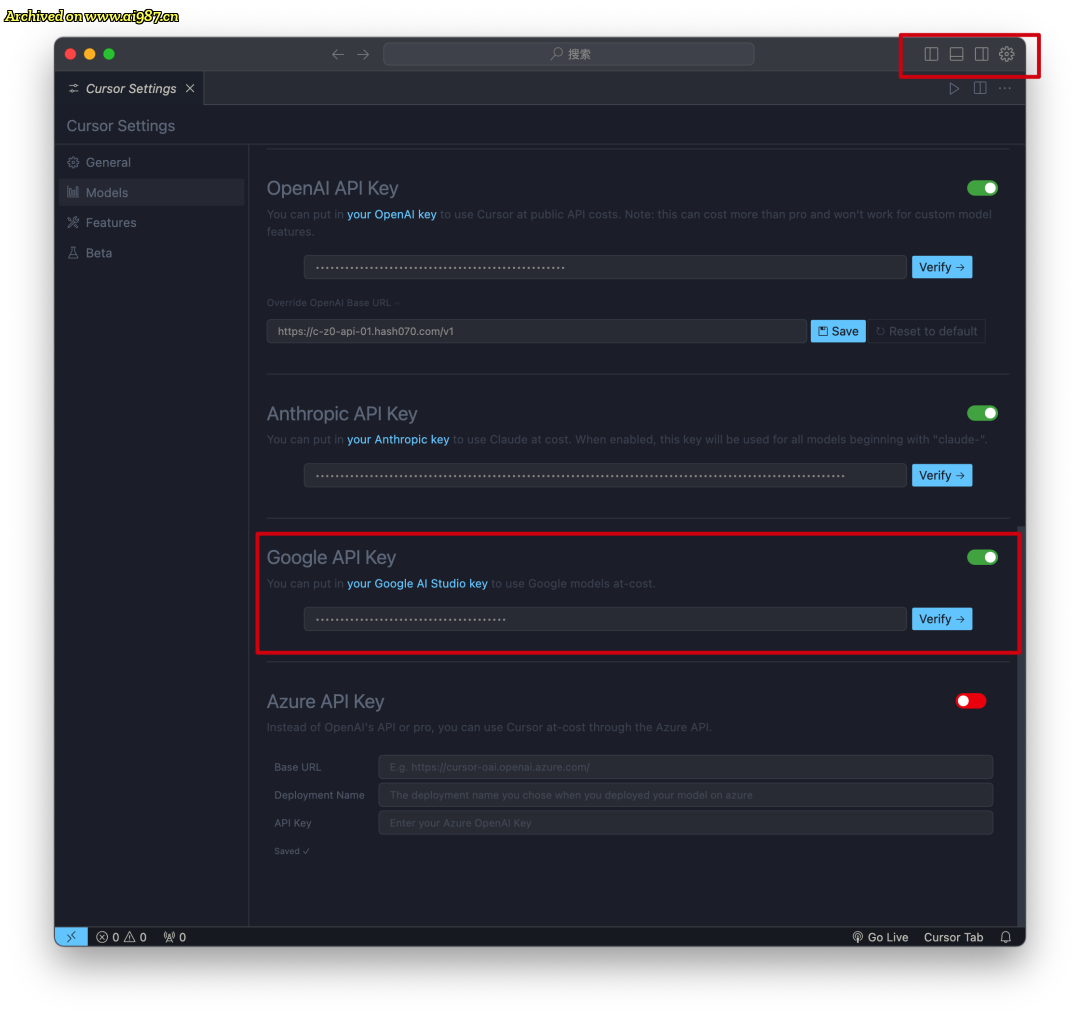
Cursor原生支持Gemini
给大家看看实际生成的速度:
二、网页 & PDF翻译
沉浸式翻译,也是老朋友了,
基本上网页、PDF翻译都已经是主力工具,我额外会搭配一个 Bob 来满足更灵活的划词翻译和图片翻译。
因为这两款软件原生就支持 Gemini API Key,
设置上基本没有难度:
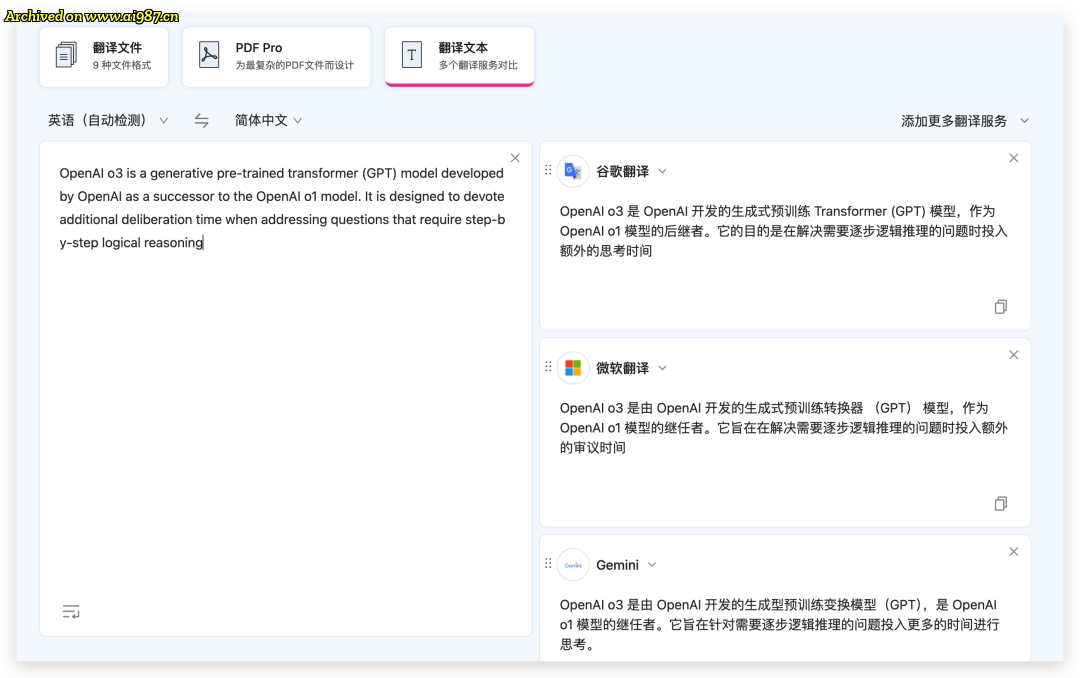
沉浸式翻译可以同时对比多个服务
Bob的设置界面
1.5-flash 的翻译速度还是蛮快的,虽说比不上非大模型的翻译接口,但胜在翻译质量是真的高。
不得不说,Gemini 2.0 这个实时语音加屏幕获取太有用了。体验感比 GPT mac 应用的实时屏幕更加丝滑。
这次用的是这款软件:https://www.dinopal.ai,
跟官网相比的话,多支持了中文聊天。
视频里我就尝试让 Gemini 帮我调整生成的图片风格,整体感觉可以充当聊天助理,要用在实时辅助的话,还是有一段距离的。
也期待后续能跟 AI 眼镜、AI 耳机联动起来,搞点新花样。
视频剪辑 & 辅助视频生成
Gemini能看懂多模态,输入多模态的好处还有更多。
一开始是 @晨然 测试 Gemini 自动剪辑的时候,发现 2.0 可以直接理解到精确毫秒的信息。而且在没有给大量 prompt 情况下给出了这个效果的剪辑,剪除了气口,保留了有效信息。
而 @海辛 根据这个特点实现了控制时间轴的视频生成,简单来说就是靠在 prompt 上写上具体的时间节点来控制镜头的运动,
具体的步骤就是:
- 在 AI Studio 选择 Starter APPs
- 然后选择 Video Analyzer
- 将视频上传选择 Custom
- 输入下面提示词
- 然后等待 Gemini 生成提示词输入海螺进行文生视频
<提示语>
视频每一个分镜的开始时间和画面详细描述,时间需要精确到小数点后两位,画面描述需要非常详细,比如环境描述、人物表情穿着、氛围等
</提示语>
关键这还是有论文支持的(666)。

素材来源:@时辰
@歸藏 还专门做了个内容复制,
而且还有衍生的玩法,我做了一个卡比兽和可达鸭推倒比萨斜塔的视频,可以上传到 AI Studio,让 Gemini 给出合适的音效建议,然后就可以在11labs里制作出合适的音效。
写在最后
可以说,有了Gemini API Key后,起码能顶五个AI应用。
这两个月没白等啊!
如果说 Gemini 1.0 是关于组织和理解信息,
那么 Gemini 2.0 就是让信息变得更加有用。
这就是人工智能的升级,
和人类的升级一样,
从最初的石器和狩猎,
演变到今天操控庞大的信息网。
我已经迫不及待地想看看,
下一个时代会带来什么。
@ 作者 / 卡尔 & 阿汤@ 动手学AI知识库 / learnprompt.pro
出处:微信公众号 @卡尔的AI沃茨