据 ai987.cn 于 2025 年 11 月 26 日收到的消息 ‣ 当业界普遍认为 AI 发展的剧本是“英伟达卖铲子,OpenAI挖金矿”时,谷歌通过发布 Gemini 3 向世界展示了另一种可能:如果自行打造全自动挖掘机,还需要依赖别人的铲子吗?

在 Gemini 3 与 Nano Banana Pro 正式亮相之前,黄仁勋和奥特曼都表现出极大的自信。与此同时,英伟达和 OpenAI 的业务正迎来高速增长期。

Nano Banana Pro 生成的示例图展示了新模型的强大创意能力。
Gemini 3 的全线发布瞬间打断了原本的“双赢”局面。彭博、财富等媒体直接指出:“谷歌这家曾被认为在 AI 时代稍显落后、甚至有些沉睡的巨头,正在全面觉醒。”
在 OpenAI 的路线图中,AI 发展一直遵循一种简化而自信的“暴力美学”——Scaling Law。OpenAI 坚持只要数据更多、算力更强,模型就会无限提升,从 GPT‑3 到 GPT‑5、GPT‑5.1,再到明年的 GPT‑6,目标直指通用人工智能。
相较之下,英伟达的商业模式更为直接:它自视为 AI 时代的唯一“卖铲子”者,所有 AI 公司几乎都必须排队缴纳“GPU 税”。然而,近期的硅谷夜色格外漫长。
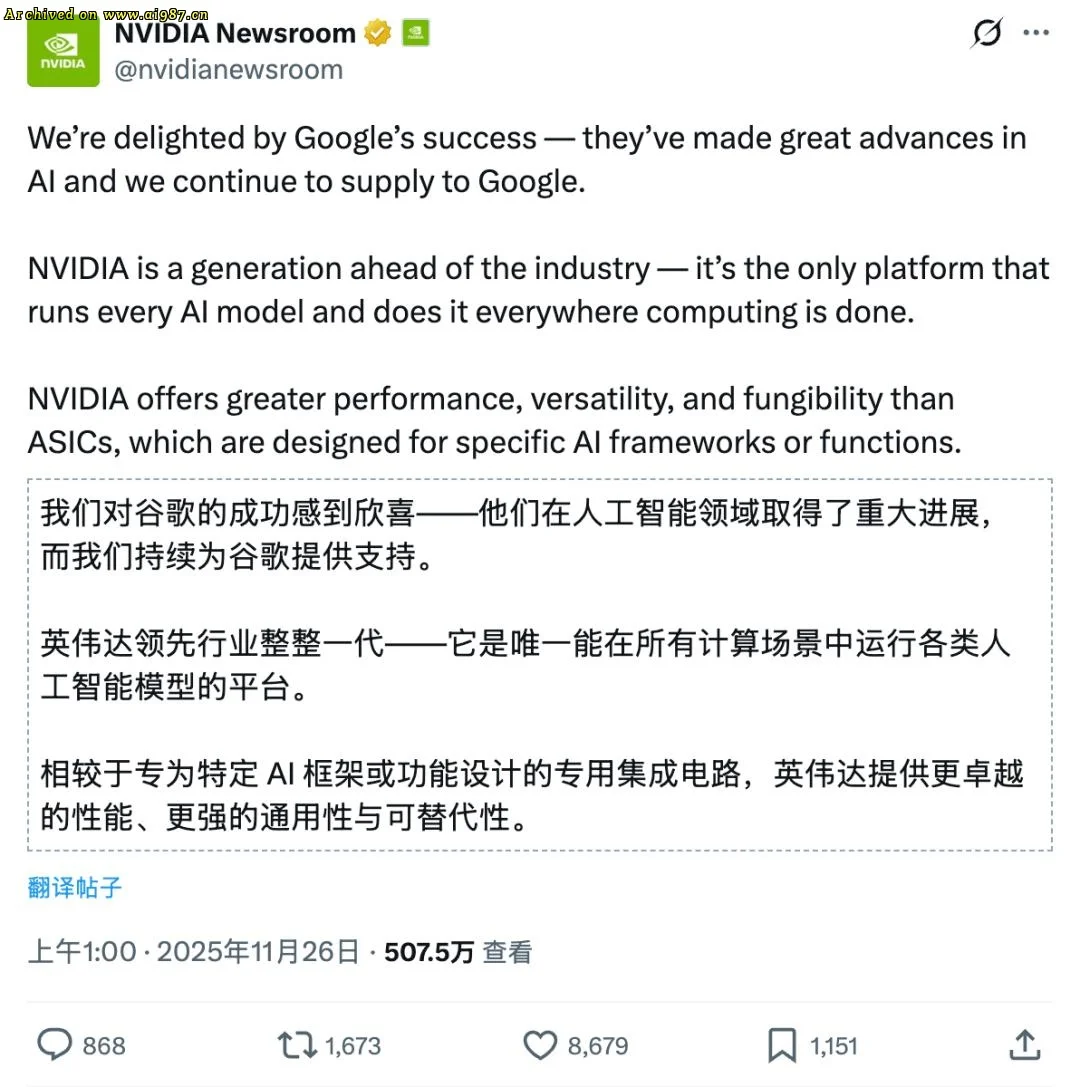
当奥特曼在深夜推特承认“OpenAI 在某些关键维度上确实落后”,全球投资者仍在消化信息。随后英伟达股价下跌,官方在 X 平台发表长文辩护,强调 CUDA 生态的不可替代性。
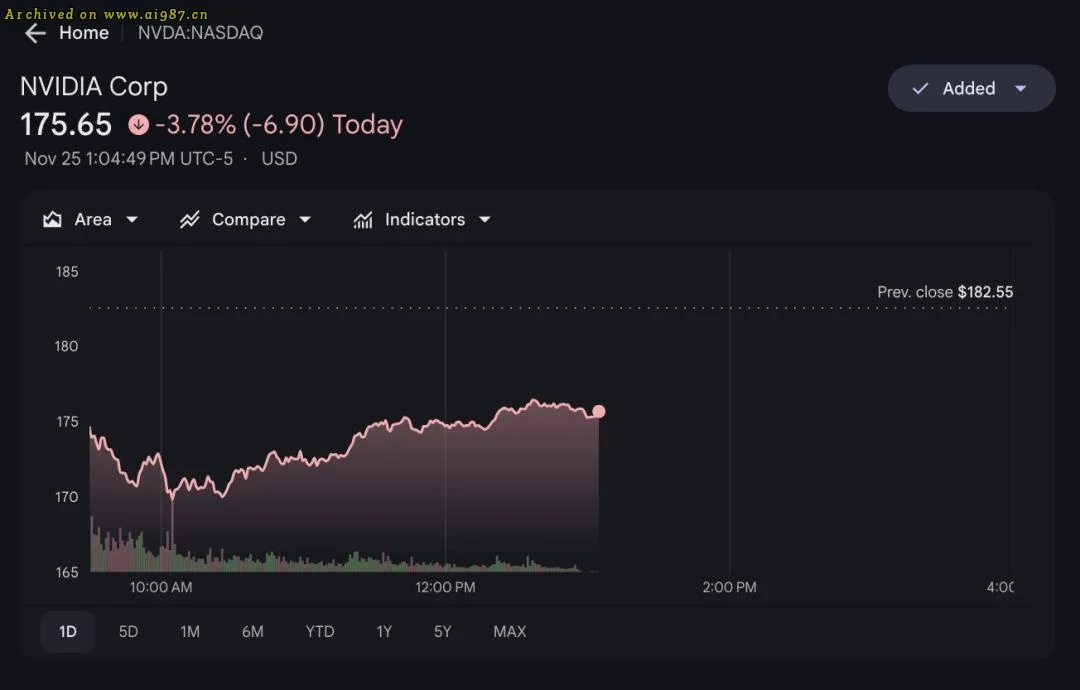
英伟达的回应透露出一丝焦虑:虽然它在所有计算场景中保持领先,但 Gemini 3 的出现让它的算力垄断受到挑战。
Gemini 3 的发布不仅是一次模型升级,更是一场“降维打击”。它左拳击碎了 OpenAI 的模型护城河,右脚踢翻了英伟达的算力神坛。
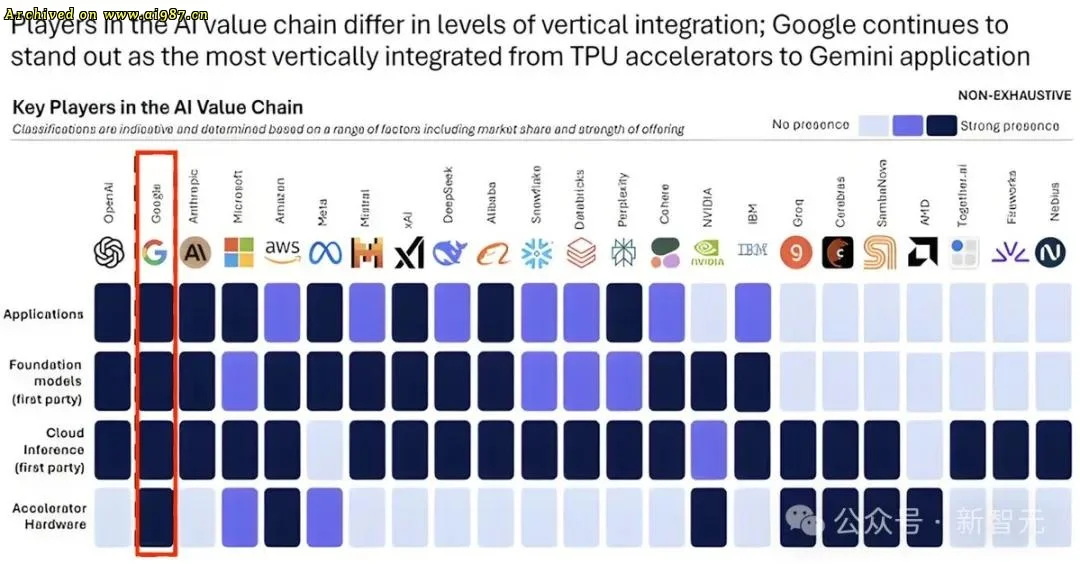
过去的 AI 叙事将英伟达定位为“收税者”,OpenAI 为“布道者”,而谷歌、Meta、Anthropic 等仅是追随者。Gemini 3 改写了这一格局,使得两大竞争者感受到前所未有的压力。

如果你近期尝试与 Gemini 3 对话或使用 Nano Banana Pro 生成图像,你会发现无需英伟达芯片,也不必等候 OpenAI 的新模型,单凭 TPU 就能训练出顶级 AI。
第一拳:打懵 OpenAI,从“堆参数”转向“原生思考”。过去两年,OpenAI 依赖 Scaling Law 的优势取得进展,但 Gemini 3 不仅更强大,还展现出异常奇特的创意表现,尤其是 Nano Banana Pro 在社交平台的广泛传播。
以下图片全部由 Gemini 生成,提示词极其简短,甚至比谷歌早期的自然语言理解还要直接。

一句话生成的各种战力排行榜

一句话生成的鬼灭之刃版本排行榜

一句话生成的知识绘本与解读
一句话生成的表情包

一句话生成的表情包

一句话将低分辨率图像精准放大至 4K 画质

它使用真实笔迹正确回答了提问,展示了惊艳的案例。
Gemini 3 首次实现了原生多模态的终极形态。此前的模型(包括 GPT‑4o)仍是将视觉、听觉和语言功能拼接的“怪人”。Gemini 3 天生具备感官互通能力,能够直接理解视频的光影和动态,而非先转化为文字。
这种设计带来了极低的延迟和敏锐的直觉。正如诺贝尔经济学奖得主丹尼尔·卡尼曼在《思考,快与慢》中提出的系统1(快思考)与系统2(慢思考)模型,Gemini 3 在硅基芯片上实现了系统2 的常态化。

OpenAI 的 o1 模型开启了“慢思考”时代,但更像是外挂插件。Gemini 3 将逻辑推理能力内化,无需用户显式提示即可在后台自动判断是使用直觉还是调动深度推理。
第二脚:踢翻英伟达,摆脱 CUDA 依赖。长期以来,AI 企业普遍依赖英伟达的 H100、GH200 等芯片以及 CUDA 生态。谷歌通过自研的最新一代 TPU——Ironwood,撕开了这道铁幕。
Gemini 3 训练使用的正是谷歌自研的 TPU 集群,计划通过 TPU@Premises 项目将算力直接卖给竞争对手,甚至宣称要夺取 英伟达 10% 的营收。Meta 已经开始转向使用谷歌的 TPU。

Gemini 3 完全在自研 TPU 上训练,这意味着谷歌不再需要向英伟达缴纳“苹果税”。每次 OpenAI 训练模型都需花费数亿美元购买英伟达 GPU,而谷歌的成本可能只有对手的一半。
软硬一体的高效协同让算力利用率突破行业上限。英伟达在 X 上的辩护显得苍白,因为市场已经听懂了谷歌的暗示:如果最强模型不需要英伟达 GPU,英伟达 80% 的毛利率还能维持多久?
Ironwood(第七代 TPU)被称为“铁木”,是谷歌迄今为止性能最强、能效最高的芯片,专为大规模推理型 AI 模型设计。

Ironwood 的三大特性包括:专为推理时代量身打造,提供高吞吐、低延迟的计算能力;构建庞大的算力网络,单个计算集群可容纳 9,216 颗芯片,芯片间互联速率达 9.6Tb/s;以及由 AI 赋能的硬件设计,DeepMind 与 TPU 工程团队协同创新,实现代际提速。
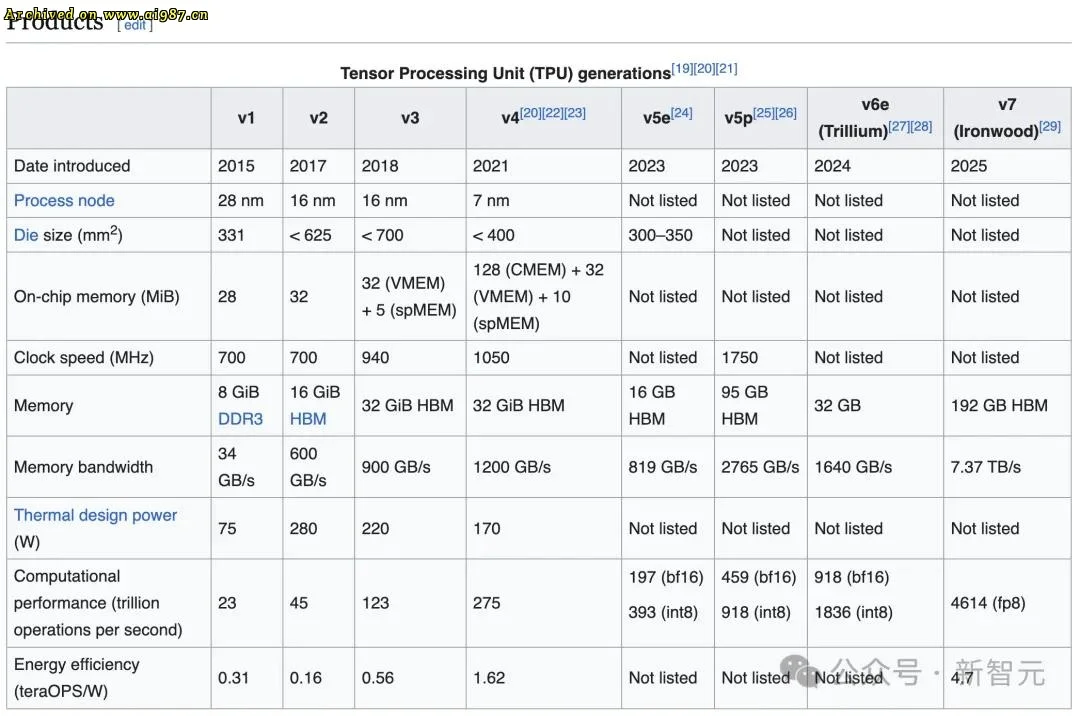

Ironwood 体现了谷歌全栈 AI 的优势:数据、算法、硬件、云端全链路自研,使得模型始终基于最新代际 TPU 训练,显著提升效率。

谷歌的“核聚变”时刻来自于组织结构的整合。过去 DeepMind 与 Google Brain 分属不同团队,内部资源分散。如今合并后,谷歌打通了“任督二脉”,并依托 YouTube、Search、Android 等平台形成强大的数据飞轮,为多模态训练提供丰富素材。
创始人谢尔盖·布林重返谷歌山景城总部,亲自参与代码编写,推动 Gemini 3 项目加速,解决长逻辑链推理的“长尾问题”。他的参与被视为对公司技术方向的强力背书。

Gemini 3 的出现标志着 AI 战争进入下半场。上半场的竞争围绕“谁的铲子好(英伟达),谁的挖掘快(OpenAI)”。下半场则是芯片、算力、全栈能力、人才与架构的全方位较量。
OpenAI 创始人之一、被誉为最接近 AGI 的 Ilya 最近接受采访,指出 Scaling 时代已结束,AI 正向研究时代转型。这一观点对依赖 Scaling Law 的 OpenAI 不利,却为拥有 DeepMind 的谷歌提供了助攻。

Google 官方博客在 Gemini 3 爆火后快速发布了关于最新 TPU 的介绍,强调三大关键特性,并暗示这些技术将重塑 AI 生态。

多年以前,谷歌发布 Transformer 论文,开启了 AI 时代的认知革命。随后 DeepMind 负责人哈萨比斯曾限制工程师对外发表核心论文,以保持竞争优势。

如果 Ilya 的观点成真,明年 AI 的话语权可能从 OpenAI 回落到谷歌手中,因为外界仍不清楚谷歌内部藏了多少未公开的技术。

面对谷歌的 TPU 竞争,英伟达计划向 Meta 注入巨额投资,以换取其继续使用英伟达芯片的承诺。英伟达凭借 73% 的利润率和预计 9700 亿美元的自由现金流,正尝试用资本手段构建新的护城河。
综合自网络信息