
今天凌晨五点,Qwen 3 正式发布和开源,make China great again !
省流版重点信息汇总如下
1、模型能力登顶,top 1 的开源模型
2、从 0.6B 到 32B 再到 235B,各个尺寸模型都有
3、所有模型都是混合推理模型
4、Agent 能力进一步增强,且 支持最近大火的 MCP
5、成本低
体验地址:
1、https://huggingface.co/spaces/Qwen/Qwen3-Demo
2、https://chat.qwen.ai/
3、https://www.tongyi.com/qianwen/
这三个地址都可以去体验,第一个是 HF 部署的,会比较慢。第二个是全球访问,可以用 github 或者谷歌邮箱登录,第三个是国内版,用手机号可以直接登录。
从官方发布的评测来说,旗舰级要好于 OpenAI O3 mini、DeepSeek R1 等模型,实力强劲。这里采用了新的命名方式,Qwen3-235B-A22B 的含义是总参数 235B,22B的激活参数,因此在实际使用的时候,推理时延会更低。
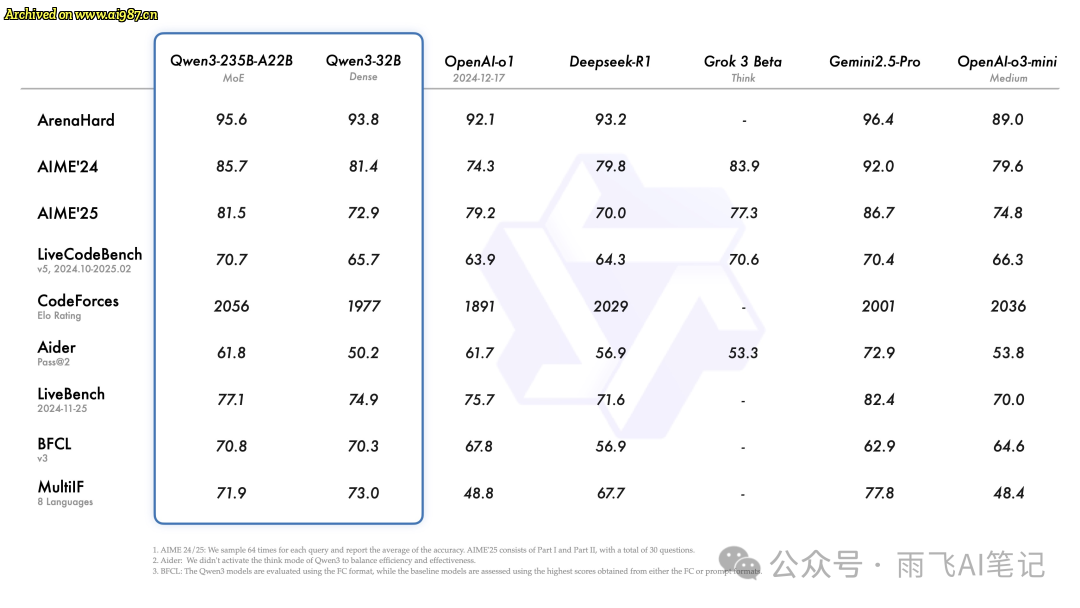
代码能力方面,根据 karminski-牙医大佬实测,235B 模型在排行榜上位于第四名,仅次于 Gemini 2.5 pro 和Claude 3.7、3.5 模型。
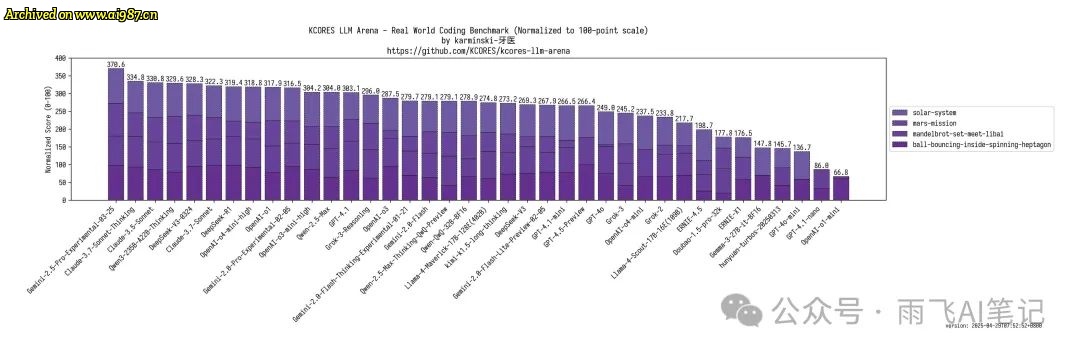
有想在本地部署模型去写代码的,可以考虑加显卡了。
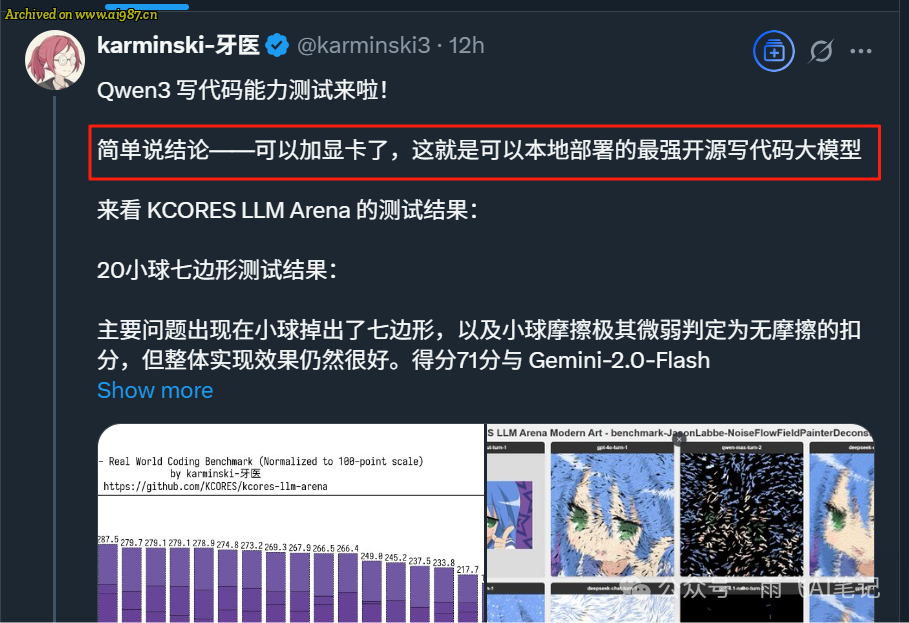
下面是模型使用思路,

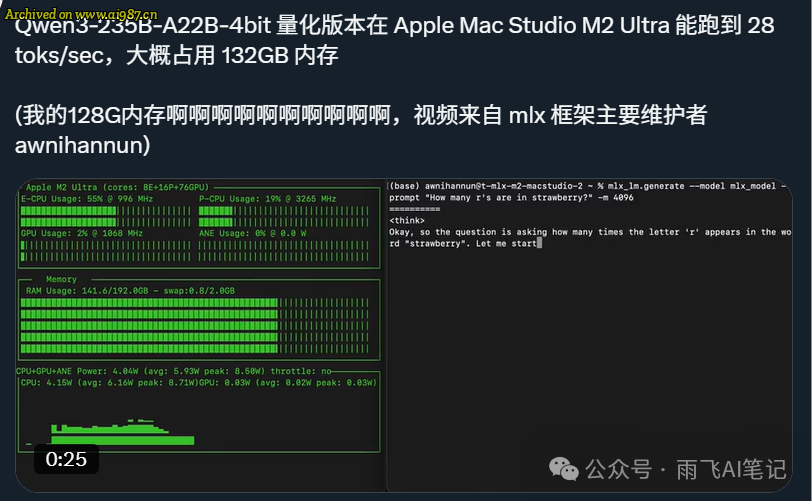
在 MAC 下,4 比特量化部署,需要 130 多 G 的内存。内存占用进一步降低,适合 AI 极客和爱好者。
最后,谈点雨飞自己的思考。 Qwen 3 模型,不仅有种很强的编码能力,也可以出色的支持 Agent 以及 MCP,对于一些企业有隐私和安全性要求来说,无疑是一种很好的选择。
另外,这次旗舰模型的成本约为之前模型的三分之一,成本更低,效果更强。由于模型本身的能力是 AI 编程工具中很重要的一环,可见后续各家应该会尝试接入该模型。
那么如何选择 AI 编程工具,或者去付费,第一个就是模型本身,只有 top 的模型才能发挥更好的效果,其次, RAG 和长上下文的能力非常关键。目前,能做好 RAG 和长上下文的工具不多,因此按年付费并不是一个很好的策略。
换句话说,AI 编程工具本身护城河很低,一旦没有持续更新,就会被后来居上。顺便问问,你现在用了多少个编程工具呢
官博和模型地址: Blog: https://qwenlm.github.io/blog/qwen3/
GitHub: https://github.com/QwenLM/Qwen3
HF:https://huggingface.co/Qwen
评测地址:https://github.com/KCORES/kcores-LLM-Arena
出处:见配图右下角